FuseCap
Leveraging Large Language Models for Enriched Fused Image Captions
Technion - Israel Institute of Technology




Abstract
The advent of vision-language pre-training techniques enhanced substantial progress in the development of models for image captioning. However, these models frequently produce generic captions and may omit semantically important image details. This limitation can be traced back to the image-text datasets; while their captions typically offer a general description of image content, they frequently omit salient details. Considering the magnitude of these datasets, manual reannotation is impractical, emphasizing the need for an automated approach. To address this challenge, we leverage existing captions and explore augmenting them with visual details using "frozen" vision experts including an object detector, an attribute recognizer, and an Optical Character Recognizer (OCR). Our proposed method, FuseCap, fuses the outputs of such vision experts with the original captions using a large language model (LLM), yielding comprehensive image descriptions. We automatically curate a training set of 12M image-enriched caption pairs. These pairs undergo extensive evaluation through both quantitative and qualitative analyses. Subsequently, this data is utilized to train a captioning generation BLIP-based model. This model outperforms current state-of-the-art approaches, producing more precise and detailed descriptions, demonstrating the effectiveness of the proposed data-centric approach. We release this large-scale dataset of enriched image-caption pairs for the community.
Method
Our framework begins with the enrichment of existing image captions using the proposed FuseCap strategy. Visual experts extract meaningful information from images. This information is then fused with the original captions by an LLM Fuser, resulting in rich captions. Following this, image datasets, coupled with these enriched fused image captions, are utilized to pre-train and fine-tune a comprehensive image-captioning model.
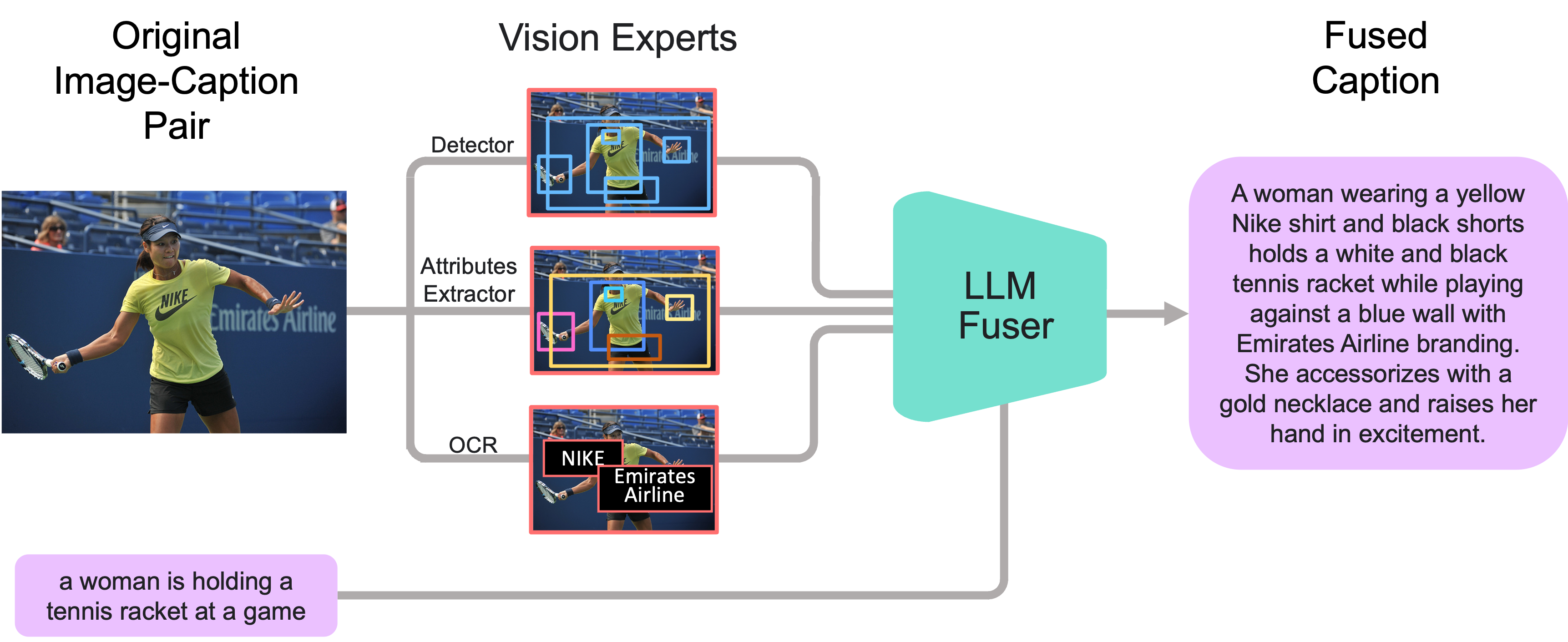
(A) Fusing Enriched Captions

(B) Training a Captioning Model
FuseCap Dataset Examples













Trained Captioning Model Examples














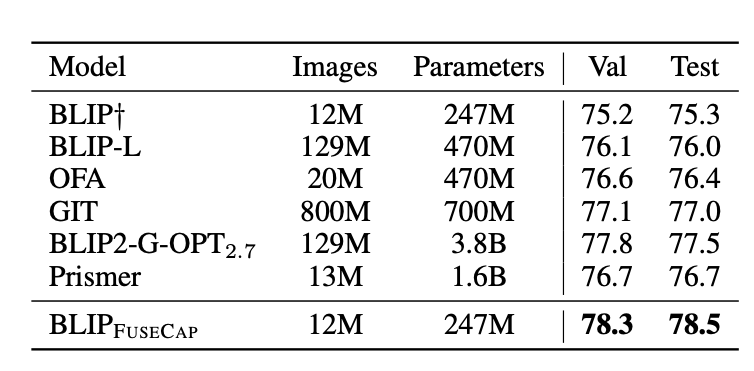
Results
Our captioning model surpasses the performance of leading state-of-the-art captioning models on the COCO dataset in terms of CLIPScore.
BibTeX
@article{rotstein2023fusecap,
title={FuseCap: FuseCap: Leveraging Large Language Models for Enriched Fused Image Captions},
author={Rotstein, Noam and Bensaid, David and Brody, Shaked and Ganz, Roy and Kimmel, Ron},
journal={arXiv preprint arXiv:2305.17718},
year={2023}
}